반응형
엑셀로 받게되는 다량의 데이터를 어떻게 하면 INSERT문을 만들어서 쉽게 Database에 입력할 수 있을까?
에 대한 대답으로 스터디를 시작한다.
1. TESTTBLE을 만들어줌

2. 엑셀 데이터
3. 해당코드값에 따른 값을 데이터베이스에 넣어줄건데, Y/N 여부가 N인경우 VALUE4에 VLUE3를 중복해서 넣는다고 가정
INSERT INTO TESTTBLE ('CODE', 'VALUE', 'VALUE2', 'VALUE3', 'VALUE4')
VALUES ('A','H','K','M')이런식으로 24번을 다 넣어주어야할까?

아니다~!
엑셀의 좋은기능을 한번 살펴보자
해당 셀옆에 ="" 를 쓰면 된다.
큰따옴표안에, 생성할 쿼리를 작성해주는데,
셀을 지칭할때에는 "&셀번호&" 이렇게 입력해주면된다.
그리고 아래로 쭈욱~ 스크롤내려주면 이와같이 대량의 INSERT문이 생성됨.
| ="INSERT INTO TESTTBL VALUES('"&A2&"','"&B2&"','"&C2&"','"&D2&"','"&E2&"');" |
해당쿼리를 실행시키면 잘들어가는것을 볼 수 있다.
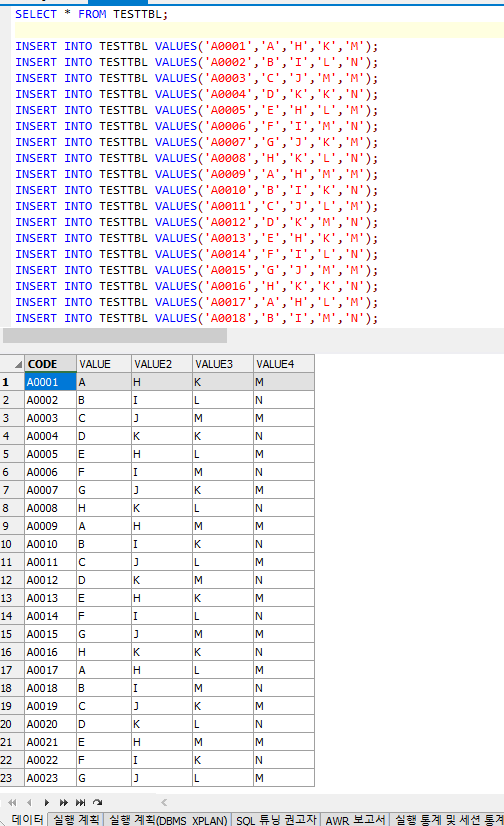
앗 그런데우리는 y/n여부에따라 네번째컬럼의값을 다르게하기로 했었다.
그렇다면 UPDATE문을 이용한다.
| ="UPDATE TESTTBL SET VALUE4= '"&D22&"' WHERE CODE = '"&A22&"';" |
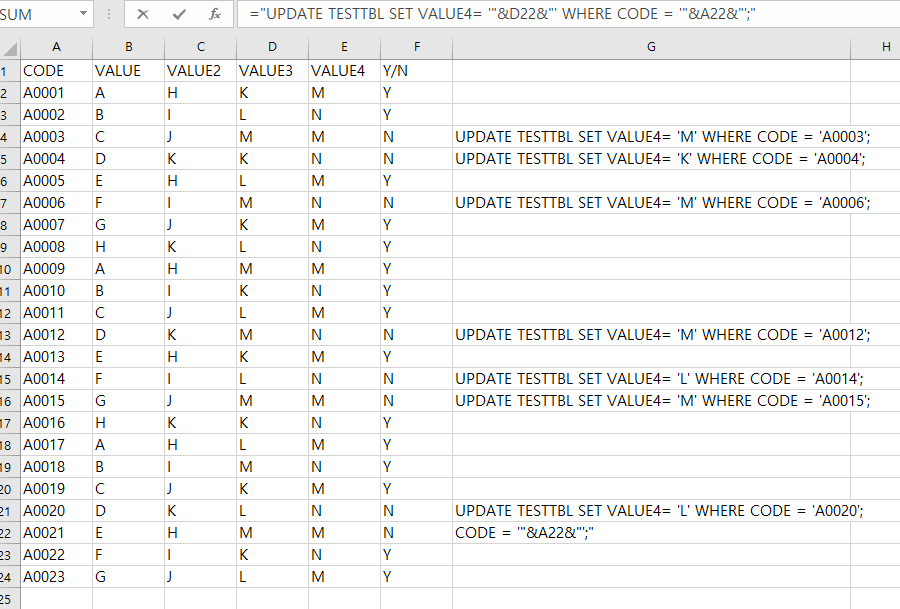
해당쿼리실행후
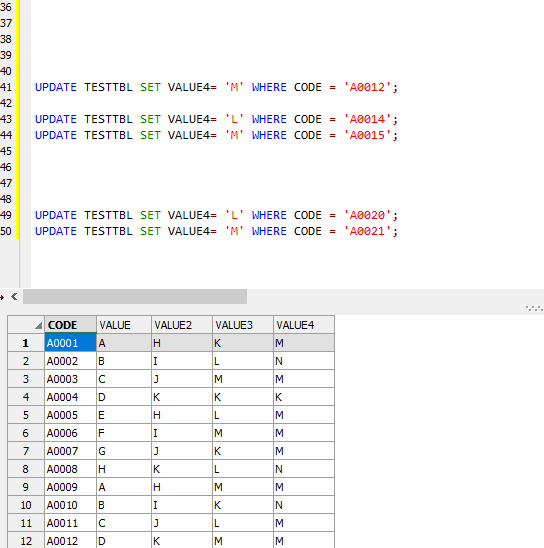
잘업데이트된것을 볼 수 있다!
끝!
반응형
'ORACLE > ORACLE함수' 카테고리의 다른 글
| [ORACLE(TO_DATE) 개발에선되는데 왜 운영에선 안되요?] (1) | 2022.09.19 |
|---|---|
| [ORACLE _ ORDER BY절 안의 CASE문] (0) | 2022.09.15 |
| [ORACLE 함수 (LISTAGG) 집계함수 : 여러행을 한행에 보여주기] (2) | 2022.09.13 |
| [ORACLE 함수 (INSTR) 문자위치 찾기] (2) | 2022.09.13 |

